どうもNSZ山本です。今日はpython文字認識です。
旅行先で取った看板をブログに引用する時に使う事が有るんですが、文字に起こすのめんどくないですか。

これはブルガリアで撮影した写真です。でも英語です。
引用するのに手打ちしても良いんですが、今後の人生の事を考えると同じ事を何度もするのは効率的ではありません。
これを解決する最も早い方法はwebサービスを利用することです。極論わざわざ自分で作る必要はあんまないです。
ocr websiteでググると以下のサイトが出てきます。。
Free Online OCR – convert PDF to Word or Image to text
しかし勉強がてらやってみます。
pythonは画像処理が楽という事なのでやってみます。
今回使うのは tesseract-ocrです。
環境
mint
python3.7~
あとでよく見たら何故かインタプリタがpython3.6だったけど行けてた。
準備
tesseract-ocr インストール
Installing pyocr on Debian · Cogs and Levers
このサイトは、install pyocr とtesseractを教えてくれるサイトの中では有能でわかりやすいです。
英語だけどもその辺の日本語のサイトよりもスラっとわかります。
上のサイトの中で必要な物の内、既にインストール済のもの以外を実行していけば良いです。
最悪上から片っ端から入れていっても問題ないと思う。僕みたいな技術力の低い人は。
「もうインストールされてるわよ」って言われるとは思います。
今回の肝のtesseract-ocr のインストール部分は以下のコマンドです。
|
1 |
sudo apt-get install tesseract-ocr tesseract-ocr-eng |
英語がインストールされます。
日本語やロシア語など多言語のインストール方法
英語だけだと寂しいので他言語をインストールします。
|
1 |
sudo apt-get install tesseract-ocr tesseract-ocr-jpn |
にすると日本語も追加されました。
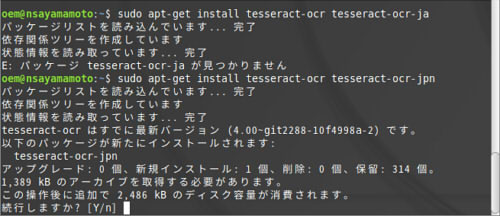
anacondaでこんな感じで入れます。上のsudo apt-get install tesseract-ocr tesseract-ocr-ja ではできません。jaはありません。 jpnが正しいです。
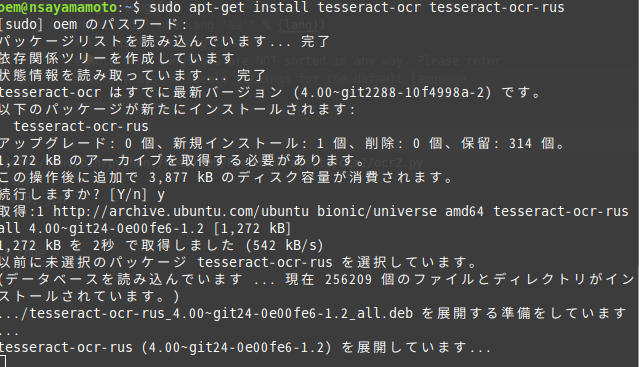
ロシア語の場合は、sudo apt-get install tesseract-ocr tesseract-ocr-rusです。
他言語は、最後の3文字を変えていけばいいだけです。
ほか
全て一気に入れる all
スペイン語 spa
フィンランド語 fin
ポーランド語 pol
デンマーク語 dan
アフリカーンス afr
ドイツ語 deu
ハンガリー語 hun
イタリア語 ita
フランス語 fra
ウクライナ語 ukr
ヘブライ語 heb
クロアチア語 hrv
中国語繁体 chi-tra
中国語簡体 chi-sim
韓国語 kor
などいろんな言語を入れたい人はこれ。挙げるときりがないのでリンク先をどうぞ。
言語一覧↓
https://askubuntu.com/questions/793634/how-do-i-install-a-new-language-pack-for-tesseract-on-16-04
アナコンダでインストールしたのに、エラーが出る場合は
- クイックフィックス
- インタプリタが違う?
- pycharm最新化してみたらいいんじゃね?(投げやり)
ocr可能か確認
pyocrやteseractをイストール後それが使えるか確認用コードで確認します。
https://qiita.com/it__ssei/items/fd804dcb10997566593b
Qittaに落ちてたヤツです。元ネタはpyocr公式のgithubです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
from PIL import Image import sys import pyocr.builders tools = pyocr.get_available_tools() if len(tools) == 0: print("No OCR tool found") sys.exit(1) # The tools are returned in the recommended order of usage tool = tools[0] print("Will use tool '%s'" % (tool.get_name())) # Ex: Will use tool 'libtesseract' langs = tool.get_available_languages() print("Available languages: %s" % ", ".join(langs)) lang = langs[0] print("Will use lang '%s'" % (lang)) |
こんな感じでOKが出たら実際に読み込んでみましょう。(jpnを入れたら,Available language: に jpn が追加されます。)
実際にやってみた
ソースコード
ソースコードはここから頂きました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
from PIL import Image import sys import pyocr import pyocr.builders tools = pyocr.get_available_tools() if len(tools) == 0: print("No OCR tool found") sys.exit(1) # The tools are returned in the recommended order of usage tool = tools[0] print("Will use tool '%s'" % (tool.get_name())) # Ex: Will use tool 'libtesseract' langs = tool.get_available_languages() print("Available languages: %s" % ", ".join(langs)) lang = langs[0] print("Will use lang '%s'" % (lang)) # Ex: Will use lang 'fra' # Note that languages are NOT sorted in any way. Please refer # to the system locale settings for the default language # to use. txt = tool.image_to_string( Image.open('iroha.png'), lang="eng", builder=pyocr.builders.TextBuilder(tesseract_layout=6) ) print( txt ) # txt is a Python string |
言語を変えるには、下から5行目のeng をjpnとかrusにすればOKです。
英語スキャン
目当ての写真をスキャンします。

流石に元の画像では無理に決まっているので、明度とコントラストを上げて認識しやすいようにします。
画像形式は
pngもjpgも通ります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
/home/oem/PycharmProjects/ocr2/venv/bin/python /home/oem/PycharmProjects/ocr2/ocr2.py Will use tool 'Tesseract (sh)' Available languages: eng, osd, jpn Will use lang 'eng' 1 ーー / - レ 1 M HH包 PEACE 上 LU | ut [ 3 ) oF PLOVDI THE CHiLDREN 5 RAILWAY xTTRACTION 5 A MARROW AT 、 5計 nAlLWAY SITUATEP jrTHE FOOT OF ruE YOUTH HILL IN PLoVDIV っ rr Jas OPENED UNDEFT THE NAME BANNER OF PEACE CHiLDREN ぅ 回 回 | RAILWAY ON 23 SEpTEMBETy 1979.1HE RAILWAY LINE is ABOUT 1 半半2 g50 M LONG ANP HAS A TRACK GAUGE OF 600 MM.「HE FOLLOW- ! | ' 4 Nc FAlLITiES HAVE BEEN CoNSTRUCTED ALONG THE ROUTE: 回 | (の PoEER ST 回 | ⑰ ABRIDGE | ⑰⑦ ArEVEL CROsSING WITH BARRIERS ] ⑰ ATUNNEL 1 ⑰ ATRESTLE 0 の⑦ SNow WHITE STATION | 。 ] ⑰⑦ PANORAMA sTATION < | 王者 「 THE TRIP FROM THE PioNEER STATION 1O THE PANORAMA STATION Ni ュ 6 . AND BACK TAKE> 25 MINUTES.「HE MAXIMUM OPERATIONAL SPEED | 人 OF TRAVEL OF THE BANNER OF PEACE ClLD RAILWAY TRAIN WAS 7 し 間 8.5 kM/H. 上 間韻0 TuE sEATING CAPACITY OF THE TRAIN I5 ABOUT 50 PASSENGERS: し TA THE TRAIN INCLUDES AN ENGINE AND THREE CARRIAGES. IT MAKES 因 0 。X TRAVELS A DAY. THE TICKET CO51 1 BGN[3]. CHILDREN 4 UND 硬 ER 10 YEARS OF AGE TRAVEL ACCOMPANIED BY AN ADULI・ 、 1 1 % BN、 GE 7 辺 3 ーーデーデーて 「 "8 」 0ま2ム潮緒トク 4 Process finished with exit code 0 |
流石に無理ですね。
ATTENTIONをxTTENTION と読んでますし、
CHILDREN’S をCHiLDREN’ 5 と読んでいる所も見えます。
傾いた写真では綺麗に読み取ることは難しいようです。
…
ペイントソフトで変形しトリミングもして再度実行します。
僕はsai先生が大好きです。

流石にこれなら行けるでしょ。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
/home/oem/PycharmProjects/ocr2/venv/bin/python /home/oem/PycharmProjects/ocr2/ocr2.py Will use tool 'Tesseract (sh)' Available languages: eng, osd, jpn Will use lang 'eng' OF PLOVDIy THE CHILDREN'S RAILWAY ATTRACTION IS A NARROW-GAUGE RAILWAY SITUATED AT THE FOOT OF THE YOUTH HILL IN PLovpiv. T WAS OPENED UNDER THE NAME BANNER OF PEAcE CHILDREN'S RAILWAY ON 23 SEPTEMBER, 1979.THE RAILWAY LINE IS ABOUT 950 M LONe AND HAS A TRACK GAUGE OF 600 MM. THE FOLLOW- ING FACILITIES HAVE BEEN CONSTRUCTED ALONG THE ROUTE: ⑦) PioNEER sTATioN ⑦ A BRIDGE (⑦) AiEVEL CROssING WTH BARRIERS の⑦ ATuNNEL (の A TRESTLE ⑰ SNow WHir sTAarloN の PANORAMA STATION' THE TRIP FROM THE PIONEER STATION TO THE PANORAMA STATION AND BACK TAKES 25 MINUTES. 「HE MAXIMUM OPERATIONAL SPEED OF TRAVEL OF THE BANNER OF PEAcE CHILD RAILWAY TRAIN WAS 8.5 kM/H. THE SEATING CAPACITY OF THE TRAIN IS ABOUT 50 PASSENGERS. THE TRAIN INCLUDES AN ENGINE AND THREE CARRIAGES. IT MAKES SIX TRAVELS A DAY. THE TICKET COsTs 1 BGN[3]. CHlLDREN UNDER 10 YEARS OF AGE TRAVEL ACCOMPANIED BY AN ADULT. で。マ 。 し 証人いに ASYW必洲 放し AN 7パ め 4 JMA - シバ ダダ Process finished with exit code 0 |
綺麗な読み込みになりました。
ごくまれに小文字と大文字を認識し切れてないのはありますが、許容範囲ですかね。
☑の部分が、日本語の⑦として認識されてる点と、草の絵を文字としてなんとかして読もうとpyocrが努力をしているのが笑えますね。
これで打ち込む手間が省けますし、看板を引用したいなら楽できます。
ロシア語

これが
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
Российско-японский памятник погибшим во Второй мировой войне Памятник представляет собой стилизованное под лодку бетонное сооружение, совмещающее небольшую сцену или место для проведения церемоний и места для зрителей, представляющие собой поднимающиеся амфитеатром четыре ступени — скамьи. Размеры: длина общая 12,6 м, ширина в южной части 4,5 м, в северной 6,3 м. По своей продольной оси памятник ориентирован по линии Север — Юг. «Памятник погибшим на Сахалине и Курильских островах. С мыслями и мире, в память о всех погибших на Сахалине и Курильских островах во время Второй мировой войны воздвигнут этот памятник. 1 ноября 1996 г.». «Памятник создан силами и при содействии Правительства Японии, Правительства Российской Федерации, Фонда «Японская ` Ассоциация членов семей павших», Администрации Сахалинской области, Администрации Смирныховского района. Проект Проектно- строительного бюро А/О «Кикутакэ Киёнори». Исполнители работ Корпорация «Тайсэй», Фирма «Гренада». В связи с тем, что по проекту «Сахалин-2» существующая японская рокадная дорога, проходящая в непосредственной близости от памятника, стала использоваться в качестве подъездной дороги СА-15, возникла необходимость проведения мероприятий, направленных на сохранность памятника. В итоге компанией «Старстрой» в 2007 году был разработан проект переноса подъездной дороги на 30 м к югу от памятника, устройства шлагбаума и благоустройства — территории, прилегающей к пороховым складам. Летом 2007 года компанией «Гренада» был произведен ремонт памятника и благоустройство площадки. = Информация из книги И.А.Самарина<Памятники воинской славы Сахалинской области». |
こうじゃ。
看板の汚れが = イコールとして認識している以外は大体大丈夫です。
以上です。
ocr使ってみたかったですし、ロシア語なんて絶対自力ではタイプ出来ないので、嬉しいです。
参考サイト
tesseractを使ってみよう(初心者編) – Qiita